

In the feverish race to cement dominance over the artificial intelligence computing arena, Nvidia has unsheathed its most formidable technological arsenal yet – the Blackwell B200 GPU and its monstrous amalgam, the GB200 “superchip.” A direct escalation from the wildly successful H100 AI processor that propelled Nvidia into the trillion-dollar valuation pantheon, these audacious new silicon leviathans are poised to dramatically reshape the accelerated computing landscape.
Nvidia unveils the Blackwell B200 GPU, the master of AI computing
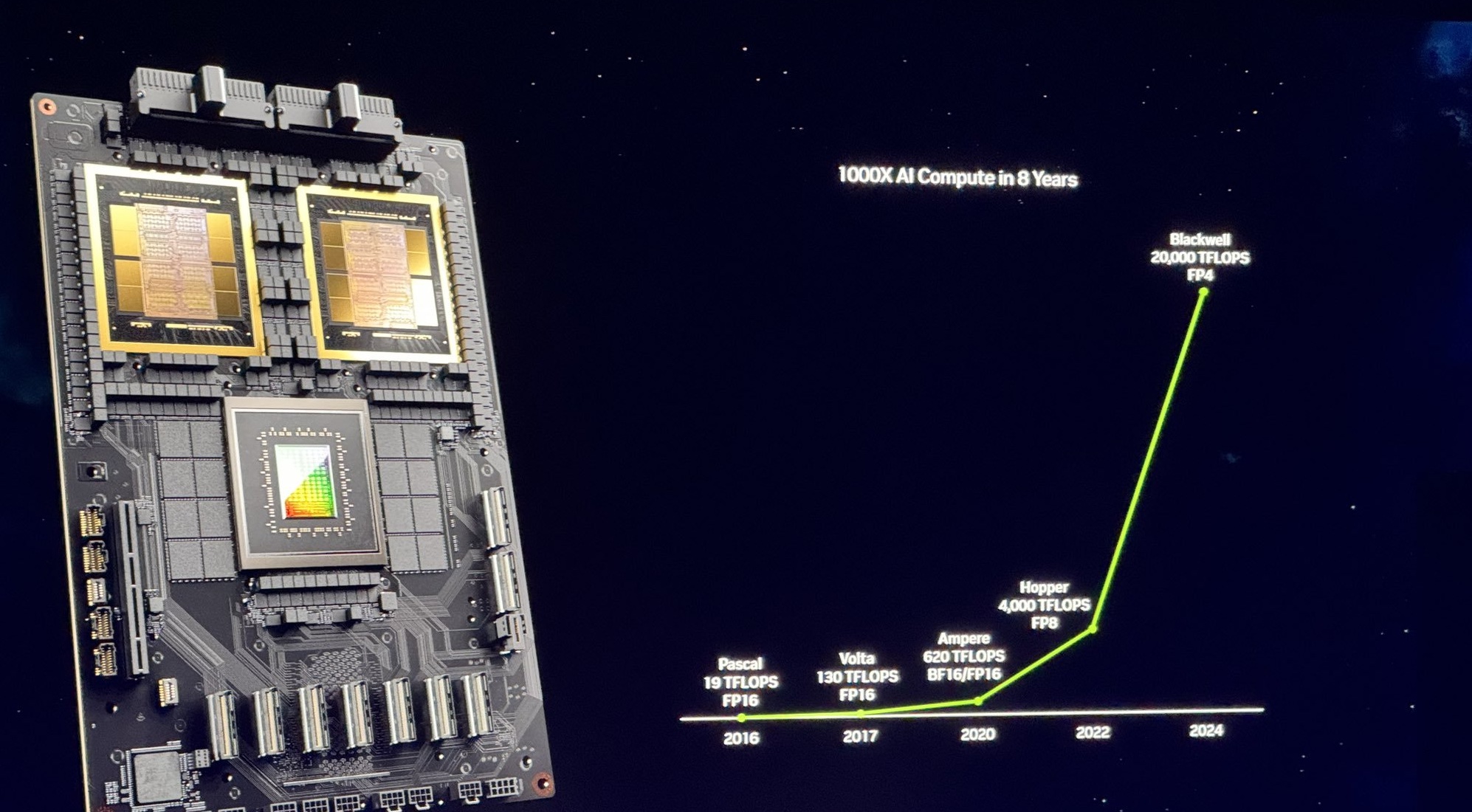
The numbers are as staggering as Nvidia’s proclamations of preeminence. The B200 GPU alone boasts a prodigious 208 billion transistors marshaled to deliver an unprecedented 20 petaflops of FP4 computational might for AI workloads. But it is the massively parallel GB200 design, wedding dual B200 GPUs to Nvidia’s brawny Grace CPU, that represents the true apex predator – a unified chiplet allegedly capable of slashing inference costs by 25-fold compared to the H100 while achieving 30 times heightened LLM performance.

“Training a 1.8 trillion parameter model would have previously taken 8,000 Hopper GPUs and 15 megawatts of power,” Nvidia CEO Jensen Huang grandly proclaimed. “Today, 2,000 Blackwell GPUs can do it while consuming just four megawatts.”
While numerical comparisons to the hallowed GPT-3 benchmark are more modest, with Nvidia claiming a 7-fold uplift over H100 performance for 175 billion parameter models, the seminal innovations propelling Blackwell’s supremacy are multifaceted. A second-generation transformer engine harnesses 4-bit precision to double model scale, bandwidth, and compute density. Simultaneously, a revolutionary 576-GPU NVLink interconnect accelerates GPU cluster communication by alleviating prior bottlenecks.

This unprecedented scaling manifests in gargantuan form factors like Nvidia’s liquid-cooled NVL72 rack, an exabyte beast containing 720 petaflops of training horsepower derived from 72 B200 GPUs intricately tethered across nearly two miles of cabling. Hyperscale cloud behemoths including Amazon, Google, and Microsoft are already slated to provision these megaclusters able to ingest models up to 27 trillion parameters – an unprecedented threshold exceeding GPT-4’s rumored 1.7 trillion parameter count.
From the DGX Superpod’s deca-petaflop fury to the Quantum-X800 InfiniBand’s networking voracity, Nvidia’s Blackwell ecosystem broadcasts an unambiguous message – a seamless, top-to-bottom vertical integration poised to cultivate the most prodigious and scalable AI endeavors yet conceived.
As artificial intelligence inexorably permutes every facet of the human experience, Nvidia has planted a seismic marker in this epochal race, resolute in its conviction that raw computational supremacy will demarcate AI’s imperators from its serfs. However titanically imposing this latest thrust, only the cosmos of innovation awaiting on the other side can prove whether Blackwell’s might can indefinitely outpace the fervid ambitions of Nvidia’s pursuers.
